

Patrick Hromniak
Visual Comparison of Natural Language Processing Pipelines
Information
- Publication Type: Bachelor Thesis
- Workgroup(s)/Project(s):
- Date: January 2019
- Date (Start): April 2018
- Date (End): January 2019
- Matrikelnummer: 1425731
- First Supervisor: Manuela Waldner

Abstract
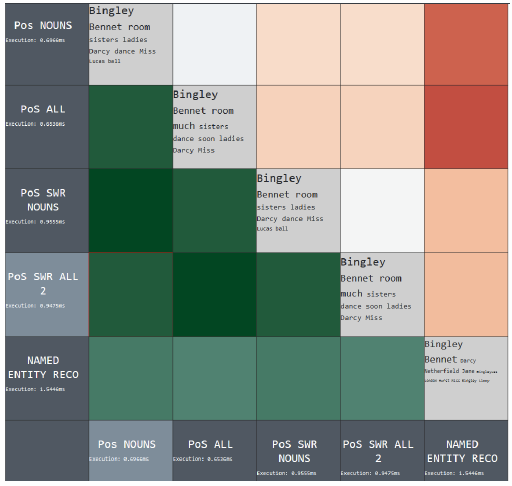
Natural Language Processing comprises a variety of operations that can be applied on raw text to extract features. The sequence of operations is called NLP pipeline. However, the sequence and parameters of these individual operations differ between applications. In each step of the ongoing sequence, a single process is performed with a specialized task. Such a task can be the determination of the end of sentences or the removal of so-called stop words. There is no best-practice which combination is most effective and accurate to determine the descriptive features (key words) of a single document. The goal of this bachelor thesis is to compute the features of different variations of NLP pipelines and visualize them as basic word clouds. It is also important to know how the resulting word cloud of each pipeline is affected by varying the order of certain steps, adding steps or removing steps. The presented interface gives an overview of performance and similarity values of each computed pipeline.Additional Files and Images

Weblinks
No further information available.BibTeX
@bachelorsthesis{hromniak-2019-vcn,
title = "Visual Comparison of Natural Language Processing Pipelines",
author = "Patrick Hromniak",
year = "2019",
abstract = "Natural Language Processing comprises a variety of
operations that can be applied on raw text to extract
features. The sequence of operations is called NLP pipeline.
However, the sequence and parameters of these individual
operations differ between applications. In each step of the
ongoing sequence, a single process is performed with a
specialized task. Such a task can be the determination of
the end of sentences or the removal of so-called stop words.
There is no best-practice which combination is most
effective and accurate to determine the descriptive features
(key words) of a single document. The goal of this bachelor
thesis is to compute the features of different variations of
NLP pipelines and visualize them as basic word clouds. It is
also important to know how the resulting word cloud of each
pipeline is affected by varying the order of certain steps,
adding steps or removing steps. The presented interface
gives an overview of performance and similarity values of
each computed pipeline.",
month = jan,
address = "Favoritenstrasse 9-11/E193-02, A-1040 Vienna, Austria",
school = "Research Unit of Computer Graphics, Institute of Visual
Computing and Human-Centered Technology, Faculty of
Informatics, TU Wien ",
URL = "https://www.cg.tuwien.ac.at/research/publications/2019/hromniak-2019-vcn/",
}