

Judith Louis-Alexandre Dit Petit-Frere
Visual Exploration of Indirect Biases in Natural Language Processing Transformer Models
[ Master thesis]
Master thesis]
Information
- Publication Type: Master Thesis
- Workgroup(s)/Project(s): not specified
- Date: 2022
- Date (Start): January 2022
- Date (End): November 2022
- TU Wien Library:
- Diploma Examination: 21. November 2022
- Open Access: yes
- First Supervisor: Manuela Waldner

- Pages: 134
- Keywords: visual exploration, visual analytics, natural language processing, bias, transformer models
Abstract
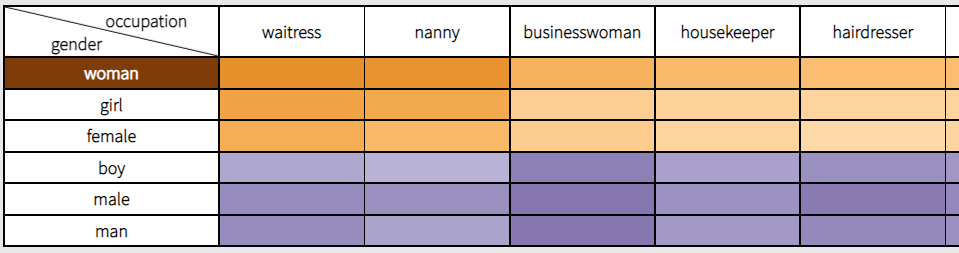
In recent years, the importance of Natural Language Processing has been increasing with more and more fields of application. The word representations, such as word embedding or transformer models, used to transcribe the language are trained using large text corpora that may include stereotypes. These stereotypes may be learned by Natural Language Processing algorithms and lead to biases in their results. Extensive research has been performed on the detection, repair and visualization of the biases in the field of Natural Language Processing. Nevertheless, the methods developed so far mostly focus on word embeddings, or direct and binary biases.To fill the research gap regarding multi-class indirect biases learned by transformer models, this thesis proposes new visualisation interfaces to explore indirect and multi-class biases learned by BERT and XLNet models. These visualisations are based on an indirect quantitative method to measure the potential biases encapsulated in transformer models, the Indirect Logarithmic Probability Bias Score. This metric is adapted from an existing one, to enable the investigation of indirect biases. The evaluation of our new indirect method shows that it enables to reveal known biases and to discover new insights which could not be found using the direct method. Moreover, the user study performed on our visualization interfaces demonstrates that the visualizations supports the exploration of multi-class indirect biases, even though improvements may be needed to fully assist the investigation of the sources of the biases.Additional Files and Images

Weblinks
- Table View
- Scatterplot
- Entry in reposiTUm (TU Wien Publication Database)
- DOI: 10.34726/hss.2022.99921
BibTeX
@mastersthesis{louis-alexandre_dit_petit-frere-2022-veo,
title = "Visual Exploration of Indirect Biases in Natural Language
Processing Transformer Models",
author = "Judith Louis-Alexandre Dit Petit-Frere",
year = "2022",
abstract = "In recent years, the importance of Natural Language
Processing has been increasing with more and more fields of
application. The word representations, such as word
embedding or transformer models, used to transcribe the
language are trained using large text corpora that may
include stereotypes. These stereotypes may be learned by
Natural Language Processing algorithms and lead to biases in
their results. Extensive research has been performed on the
detection, repair and visualization of the biases in the
field of Natural Language Processing. Nevertheless, the
methods developed so far mostly focus on word embeddings, or
direct and binary biases.To fill the research gap regarding
multi-class indirect biases learned by transformer models,
this thesis proposes new visualisation interfaces to explore
indirect and multi-class biases learned by BERT and XLNet
models. These visualisations are based on an indirect
quantitative method to measure the potential biases
encapsulated in transformer models, the Indirect Logarithmic
Probability Bias Score. This metric is adapted from an
existing one, to enable the investigation of indirect
biases. The evaluation of our new indirect method shows that
it enables to reveal known biases and to discover new
insights which could not be found using the direct method.
Moreover, the user study performed on our visualization
interfaces demonstrates that the visualizations supports the
exploration of multi-class indirect biases, even though
improvements may be needed to fully assist the investigation
of the sources of the biases.",
pages = "134",
address = "Favoritenstrasse 9-11/E193-02, A-1040 Vienna, Austria",
school = "Research Unit of Computer Graphics, Institute of Visual
Computing and Human-Centered Technology, Faculty of
Informatics, TU Wien",
keywords = "visual exploration, visual analytics, natural language
processing, bias, transformer models",
URL = "https://www.cg.tuwien.ac.at/research/publications/2022/louis-alexandre_dit_petit-frere-2022-veo/",
}