

Florian Spechtenhauser
Visual Analytics for Rule-Based Quality Management of Multivariate Data
[ thesis]
thesis]
Information
- Publication Type: Master Thesis
- Workgroup(s)/Project(s):
- Date: August 2016
- Date (Start): 2015
- Date (End): August 2016
- TU Wien Library:
- First Supervisor: Eduard Gröller

Abstract
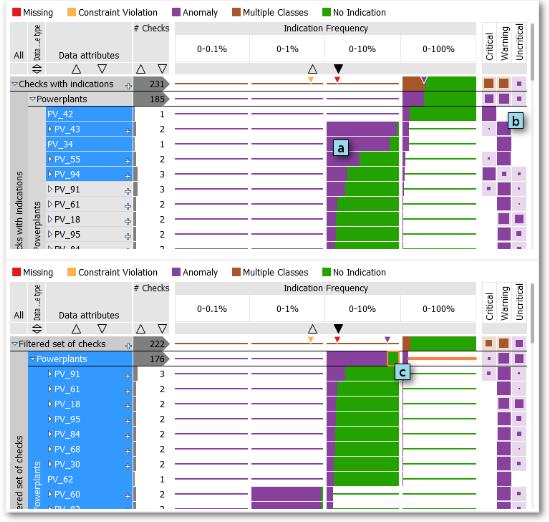
Ensuring an appropriate data quality is a critical topic when analyzing the ever increasing amounts of data collected and generated in today’s world. Depending on the given task, even sophisticated analysis methods may cause misleading results due to an insufficient quality of the data set at hand. In this case, automated plausibility checks based on defined rules are frequently used to detect data problems such as missing data or anomalies. However, defining such rules and using their results for an efficient data quality assessment is a challenging topic. Visualization is powerful to reveal unexpected problems in the data, and can additionally be used to validate results of applied automated plausibility checks. Visual Analytics closes the gap between automated data analysis and visualization by providing means to guide the definition and optimization of plausibility checks in order to use them for a continuous detection and validation of problems detected in the data. This diploma thesis provides a design study of a Visual Analytics approach, called Data Quality Overview, which provides a detailed, yet scalable summary of the results of defined plausibility checks, and includes means for validation and investigation of these results at various levels of detail. The approach is based on a detailed task analysis of data quality assessment, and is validated using a case study based on sensor data from the energy sector in addition to feedback collected from domain experts.Additional Files and Images

Weblinks
No further information available.BibTeX
@mastersthesis{Spechtenhauser_Florian_2016,
title = "Visual Analytics for Rule-Based Quality Management of
Multivariate Data",
author = "Florian Spechtenhauser",
year = "2016",
abstract = "Ensuring an appropriate data quality is a critical topic
when analyzing the ever increasing amounts of data collected
and generated in today’s world. Depending on the given
task, even sophisticated analysis methods may cause
misleading results due to an insufficient quality of the
data set at hand. In this case, automated plausibility
checks based on defined rules are frequently used to detect
data problems such as missing data or anomalies. However,
defining such rules and using their results for an efficient
data quality assessment is a challenging topic.
Visualization is powerful to reveal unexpected problems in
the data, and can additionally be used to validate results
of applied automated plausibility checks. Visual Analytics
closes the gap between automated data analysis and
visualization by providing means to guide the definition and
optimization of plausibility checks in order to use them for
a continuous detection and validation of problems detected
in the data. This diploma thesis provides a design study of
a Visual Analytics approach, called Data Quality Overview,
which provides a detailed, yet scalable summary of the
results of defined plausibility checks, and includes means
for validation and investigation of these results at various
levels of detail. The approach is based on a detailed task
analysis of data quality assessment, and is validated using
a case study based on sensor data from the energy sector in
addition to feedback collected from domain experts.",
month = aug,
address = "Favoritenstrasse 9-11/E193-02, A-1040 Vienna, Austria",
school = "Institute of Computer Graphics and Algorithms, Vienna
University of Technology ",
URL = "https://www.cg.tuwien.ac.at/research/publications/2016/Spechtenhauser_Florian_2016/",
}