

Nidham Tekaya, Manuela Waldner , Matthias Zeppelzauer
, Matthias Zeppelzauer
A Matter of Time: Revealing the Structure of Time in Vision-Language Models
In MM '25: Proceedings of the 33rd ACM International Conference on Multimedia, pages 12371-12380. October 2025.
[]
Information
- Publication Type: Conference Paper
- Workgroup(s)/Project(s):
- Date: October 2025
- ISBN: 979-8-4007-2035-2
- Open Access: yes
- Location: Dublin
- Lecturer: Nidham Tekaya
- Event: ACM International Conference on Multimedia 2025
- DOI: 10.1145/3746027.3758163
- Booktitle: MM '25: Proceedings of the 33rd ACM International Conference on Multimedia
- Pages: 10
- Conference date: 27. October 2025 – 31. October 2025
- Pages: 12371 – 12380
- Keywords: Multimodal representations, Vision-language models, Time modeling, Time estimation, Benchmark dataset
Abstract
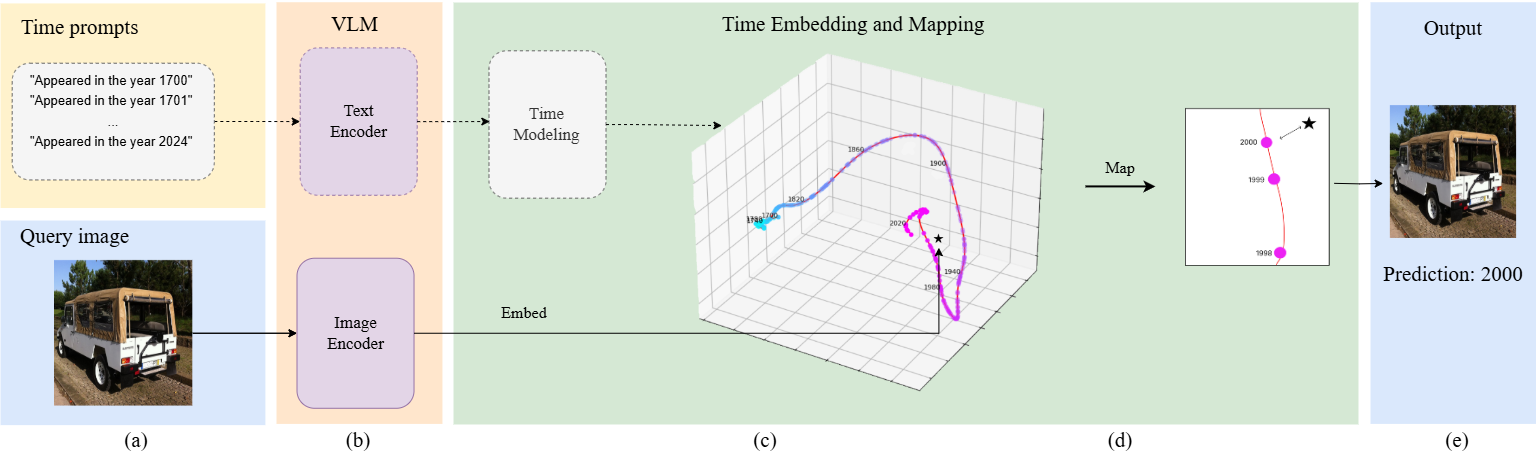
Large-scale vision-language models (VLMs) such as CLIP have gained popularity for their generalizable and expressive multimodal representations. By leveraging large-scale training data with diverse textual metadata, VLMs acquire open-vocabulary capabilities, solving tasks beyond their training scope. This paper investigates the temporal awareness of VLMs, assessing their ability to position visual content in time. We introduce TIME10k, a benchmark dataset of over 10,000 images with temporal ground truth, and evaluate the time-awareness of 37 VLMs by a novel methodology. Our investigation reveals that temporal information is structured along a low-dimensional, non-linear manifold in the VLM embedding space. Based on this insight, we propose methods to derive an explicit ''timeline'' representation from the embedding space. These representations model time and its chronological progression and thereby facilitate temporal reasoning tasks. Our timeline approaches achieve competitive to superior accuracy compared to a prompt-based baseline while being computationally efficient. All code and data are available at https://tekayanidham.github.io/timeline-page/.Additional Files and Images
Weblinks
- https://tekayanidham.github.io/timeline-page/
- Entry in reposiTUm (TU Wien Publication Database)
- DOI: 10.1145/3746027.3758163
BibTeX
@inproceedings{tekaya-2025-amo,
title = "A Matter of Time: Revealing the Structure of Time in
Vision-Language Models",
author = "Nidham Tekaya and Manuela Waldner and Matthias Zeppelzauer",
year = "2025",
abstract = "Large-scale vision-language models (VLMs) such as CLIP have
gained popularity for their generalizable and expressive
multimodal representations. By leveraging large-scale
training data with diverse textual metadata, VLMs acquire
open-vocabulary capabilities, solving tasks beyond their
training scope. This paper investigates the temporal
awareness of VLMs, assessing their ability to position
visual content in time. We introduce TIME10k, a benchmark
dataset of over 10,000 images with temporal ground truth,
and evaluate the time-awareness of 37 VLMs by a novel
methodology. Our investigation reveals that temporal
information is structured along a low-dimensional,
non-linear manifold in the VLM embedding space. Based on
this insight, we propose methods to derive an explicit
''timeline'' representation from the embedding space. These
representations model time and its chronological progression
and thereby facilitate temporal reasoning tasks. Our
timeline approaches achieve competitive to superior accuracy
compared to a prompt-based baseline while being
computationally efficient. All code and data are available
at https://tekayanidham.github.io/timeline-page/.",
month = oct,
isbn = "979-8-4007-2035-2",
location = "Dublin",
event = "ACM International Conference on Multimedia 2025",
doi = "10.1145/3746027.3758163",
booktitle = "MM '25: Proceedings of the 33rd ACM International Conference
on Multimedia",
pages = "10",
pages = "12371--12380",
keywords = "Multimodal representations, Vision-language models, Time
modeling, Time estimation, Benchmark dataset",
URL = "https://www.cg.tuwien.ac.at/research/publications/2025/tekaya-2025-amo/",
}