

Description
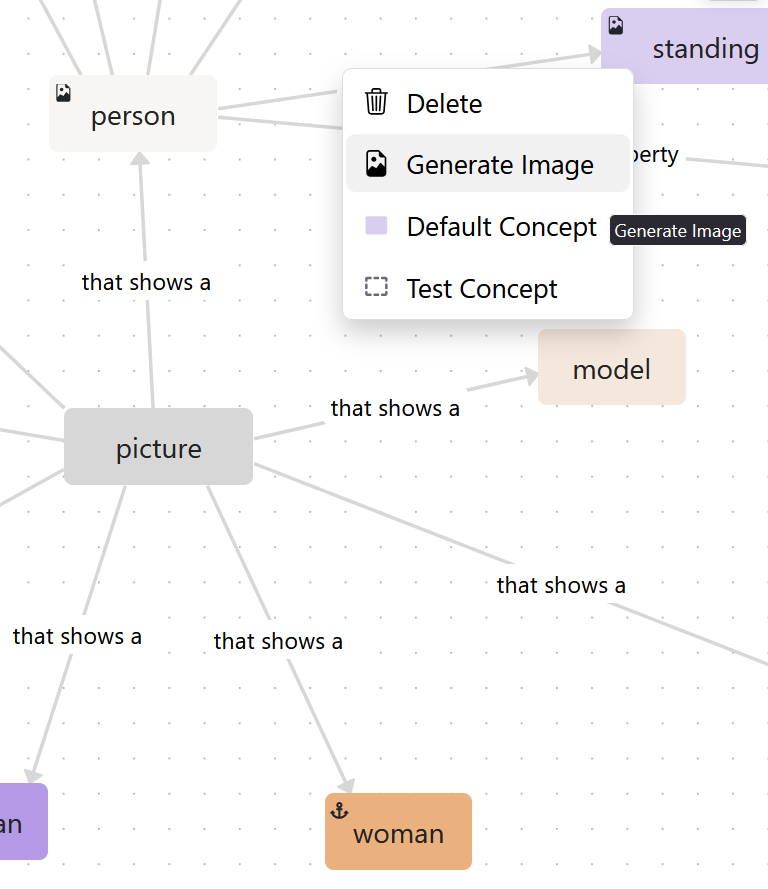
Traditional prompting interfaces commonly utilize text boxes for user input in image generation. While simple, this method can limit expressivity and makes it harder to specify structured or complex scenes. For this project you are working on an alternative input method that allows users to formulate prompts via an interactive graph. This visual approach aims to support more intuitive and flexible interaction, especially for users unfamiliar with prompt engineering.
The system will be based on an existing framework written in TypeScript/React and should support various interaction modalities (e.g., touch, mouse. Further extensions may include automatic layout methods, automatically inferring ontology-based relations between concepts (e.g., is-a, has-attribute), or evaluation of the system's usability and output effectiveness.
Tasks
- Extend an existing graph-based prompting framework into a stand-alone module
- Support multiple input modalities (mouse, touch, mobile)
- Add usability features (e.g., undo/redo, drag-and-drop editing, ...)
- Potential extensions include implementing automatic layout methods or testing user experience
Requirements
- Knowledge of English language (source code comments and final report should be in English)
- Basic programming experience (e.g., JavaScript/TypeScript), knowledge of React is advantageous
- Interest in visual interfaces, HCI, or Text-to-Image generation
Environment
The project will be implemented in an existing React project, where it should be compatible with existing use-cases.