Speaker: Sebastian Antes
Abstract
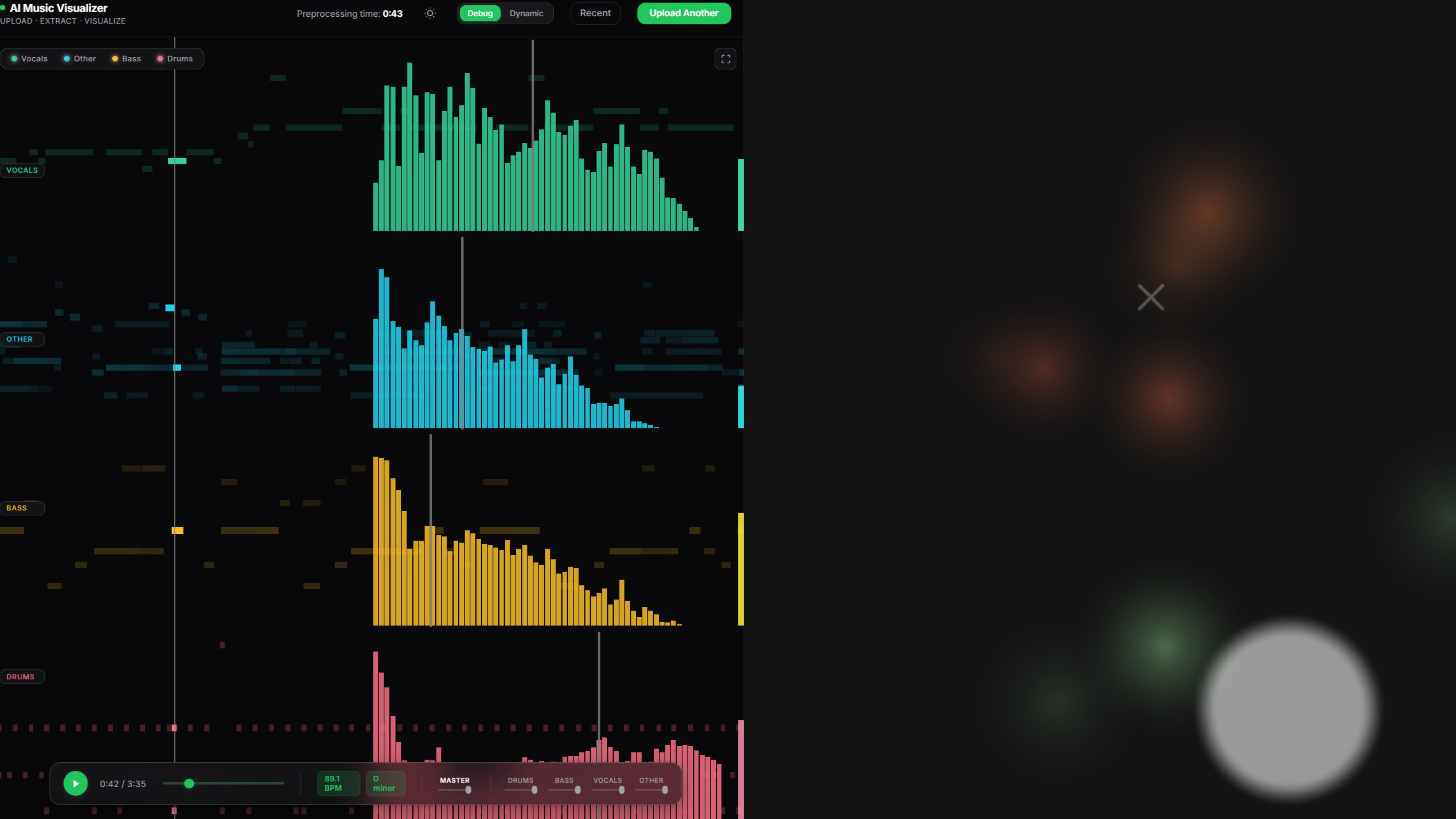
Can a Large Language Model (LLM) semantically interpret musical structures deeply enough to direct their visual representation? This thesis moves beyond generic, reactive audiovisualizers by introducing a generative configuration pipeline that leverages multi-stage LLM prompting to map structured audio analysis to the deterministic parameters of a WebGPU rendering engine. The methodology involves an offline backend stage utilizing source separation, MIDI transcription, and feature extraction to distill rhythmic, melodic, and timbral descriptors. These descriptors, alongside a structural analysis of song segments, are processed by a cascading LLM sequence to synthesize a section-aware configuration. Rather than rendering directly, the LLM selects specific shader layers and defines mappings from calibrated audio features to WebGPU shader uniforms. At runtime, these mappings are evaluated deterministically using time-synchronized feature streams, normalization ranges, and smoothing functions, allowing the visualization to adapt across song sections while preserving high-performance real-time rendering. This hybrid approach offloads aesthetic mapping decisions to an AI-guided configuration layer while maintaining deterministic visual execution. The framework is validated through a mixed-methods evaluation, combining qualitative user studies on perceptual alignment with quantitative analysis of temporal and structural correspondence between audio dynamics and the generated visual output.