Inhaltsverzeichnis
- Übersicht
- Ordnerstruktur
- Ausführen
- wikipedia-dump-extractor
- WikiVisWeb
- Benutzung der Visualisierung
- Einfügen neuer Daten
- Codedokumentation
Übersicht
Das Projekt WikiVis besteht aus mehreren Komponenten die
zusammenarbeiten: das Kommandozeilenprogramm
wikipedia-dump-extractor, die Webappliaktion WikiVisWeb sowie die
Processing-applikation wikiVis.
Das Programm wikipedia-dump-extractor dient nur zur extrahierung von
Revisionsdaten aus sogenannten stub-dump-dateien die Wikipedia
bereitstellt. Diese Dateien enthalten Revisionsdaten von mehreren
Seiten und sind meist zu groß das diese schnell verarbeitet werden
können. Das Entnehmen der Daten einzelner Seiten durch herkömmliche
Texteditoren war deshalb auch nicht möglich, weshalb dieses
Hilfsprogramm entwickelt wurde. Will man mehr als die in dieser
Abgabe bereitgestellten Seiten der Wikipedia zu der Visualisierung
hinzufügen, müssen diese hiermit extrahiert werden. Weiter
Informationen dazu finden Sie in dem Kapitel "Einfügen
neuer Daten"
WikiVisWeb ist die Webapplikation und bildet mit der
eingebetteten Processing Applikation wikiVis die eigentliche
Visualisierungsapplikation. Hierbei übernimmt die Webapplikation die
Bereitstellung und Verarbeitung der Daten, die es dann an die
Processing Applikation weitergibt. Die Processing Applikation wird
mittels Processing.js ausgeführt und stellt die bereitgestellten
Daten dar, sofern möglich. Diese Trennung ist notwendig da aufgrund
der großen Datenmengen die Berechnung im Browser nicht in
vertretbarer Zeit möglich war.
Ordnerstruktur
- Screenshot.jpg
- Homepage/
- index.html -- diese datei
- WikiVis/
- wikipedia-dump-extractor/
- bin/ -- kompilierte class dateien
- WikiVisServer/ -- jetty-runner und kompiliertes .war
file
- WikiVisWeb/ -- Die Webapplikation (Eclipse Projekt)
- wikiVis/ -- Processing Applikation
- doc/
- wikipedia-dump-extractor/ -- Doxygen Dokumentation von
wikipedia-dump-extractor
- WikiVisWeb/ -- Doxygen Dokumentation von WikiVisWeb
Ausführen
wikipedia-dump-extractor
Die ausführbaren Dateien befinden sich im bin Ordner im
wikipedia-dump-extractor Verzeichnis. Mittels folgendem Befehl
können sämtliche Artikel, die im angegeben Dump-File enthalten sind,
aufgelistet werden:
java Main <dumpfile> --list
Möchte man einen oder mehrere Artikel extrahieren, kann dies
mit folgendem Befehl erfolgen:
java Main <dumpfile> --extract <pagetitle>
[<pagetitle2>...]
Die extrahierten Seiten werden im selben Verzeichnis
gespeichert, und können zur weiteren Verarbeitung benutzt werden.
WikiVisWeb
Es müssen grundsätzlich zwei Schritte unternommen werden. Zuerst
soll der Server gestartet werde, danach kann die Startseite im
Browser aufgerufen werden. Man navigiere zum Ordner WikiVisServer. Mit folgender
Anweisung wird Jetty gestartet:
java -Xmx2048m -jar jetty-runner.jar WikiVisWeb.war
Es ist wichtig zu beachten, dass der Server genügend Arbeitsspeicher
zugewiesen bekommt, da besonders die Eigenwertberrechnungen eineges
an Ressourcen verlangt. Nachdem der Server erfolgreich initialisiert
wurde, kann die Visualisierung über den Browser gestartet werden.
Mit einem Browser der Wahl – unterstützt werden Chrome, Safari und
Firefox – wird die Visualisierung
gestartet.
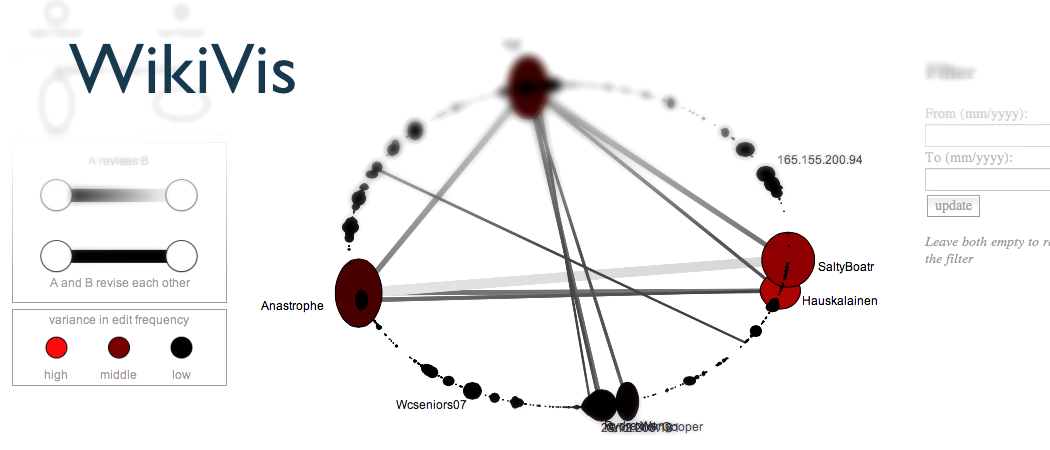
Benutzung der Visualisierung
Zuerst muss eine der zu darstellende Seiten ausgewählt werden.
Die Auflistung erfolgt auf der rechten Seite, und entspricht in
seinen standard-Einstellungen den im Paper benutzten Seiten. Nach
erfolgter Berechnung – man beachte die Rückmeldungen des Servers in
der Konsole – wird das Netzwerk mit der dazugehörigen
Gesamtübersicht visualisiert. Eine Legende erklärt wie die
verschiedenen Informationen kodiert werden, und sind nach der
Beschreibung im Paper gestaltet worden.
Möchte man einen genaueren Zeitabschnitt betrachten, so kann
über die Zeitfilter der Bereich eingeschränkt werden. Die Eingabe
der Filter verfügt über einen simplen Eingabevalidierungscheck; man
muss aber anmerken, dass nicht alle möglichen Falscheingaben
abgefangen werden. Um die Selektion zu löschen einfach die Felder
leer lassen. Es kann jederzeit ein neuer Artikel aus der Liste
ausgewählt werden.
Einfügen neuer Daten
Alle Revsisionsdaten die die Webapplikation nutzen kann müssen im data Verzeichnis
der Webapplikation liegen. Die Daten müssen dabei mit dem Programm
wikipedia-dump-extractor erstellt worden sein. Danch muss in der
Konfigurationsdatei pagedata-config.xml
noch das mapping definiert werden, welche Seite in welcher datei zu
finden ist. Bei dieser datei handelt es sich um eine Java
Properties XML datei. Die Keys entsprechen dabei dem Titel der
Wikipedia-Seite und die Werte dem namen der dazugehörigen xml datei.
Details zu dem Schema dieser Datei entnehmen Sie der Javadoc
Seite zu "Properties".
Codedokumentation
Die detaillierte Dokumentation des Codes sind der Doxygen
Dokumentation der beiden Projekte zu entnehmen: