
Informationsvisualisierung SS 2013
Lukas Meindl - 1028160 ( infovis (at) lukasmeindl . at )
Da die meisten interessanten Texte sehr lange sind, ist es oft von Vorteil sie mittels Analysierung und Zusammenfassung in eine Form zu bringen die sich visualisieren lässt. Hierbei ist die Schwierigkeit das ganze effizient zu gestalten und gleichzeitig einen Ausgleich zwischen Zuverlässigkeit und Gültigkeit des Ergebnisses zu gewährleisten. Das andere Problem bei der Visualisierung liegt in der Lesbarkeit und der räumlichen Anordnung. Die räumliche Positionierung sollte eine Bedeutung haben und gleichzeitig muss der Text noch gut lesbar sein können.
Im Paper "Mapping Text with Phrase Nets" von Hamet et al. wird eine neue Herangehensweise vorgeschlagen. Hierbei werden für die Textanalyse Syntactic Linking und Orthographic Linking präsentiert. Syntactic Linking basiert hierbei bei ihrer Implementierung auf dem Open-Source „Stanford Parser“, ist allerdings sehr rechenintensiv. Orthographic Linking erlaubt eine schnelle Analyse mittels Text-basierten Mustervergleichs. Hierbei werden regular expressions (regex) verwendet. Da nicht alle User mit regex vertraut sind, werden in dem User Interface mehrere Muster vorgeschlagen aus denen man wählen kann und dann entsprechende Wörter in die Platzhalter des Musters einfügt.
Nach der Analyse ergibt sich ein Graph aus Wörtern, die durch gerichtete Verbindungen mit anderen Wörtern verbunden sind. Da dieser Graph zu groß wäre um ihn darzustellen, wird er anschließend gefiltert. Hierbei wird er um Wörter die häufig vorkommen, aber keinen wertvollen Inhalt repräsentieren reduziert. Zudem werden nur die relevantesten Nodes (= allgemein am häufigsten vorkommende Wörter) angezeigt. Die Maximalanzahl ist hierbei user-spezifiziert.
Die Application wurde in MSVS2010 in C++ 32bit auf Windows 7 geschrieben. Das Rendering erfolgt mittels OpenGL 3.2+ Core. Als utility libraries für OpenGL wurden glfw, glew und glm verwendet.
Bei meiner Umsetzung wurde Orthographic Linking verwendet und zwar mittels Regex-Vergleich durch die RE2 library als Window-port. Link zu RE2 repository: http://code.google.com/p/re2/

Weiters habe ich CEGUI als GUI library verwendet: http://www.cegui.org.uk

Die Nodes wurden mit eigenem Code positioniert um sicherzustellen, dass die Nodes möglichst nahe sind und die Pfeile dazwischen korrekt gezeichnet werden. Die UI wurde mit CEGUI designed, welches auch für das Text-rendering verwendet. Weiters wurden einige Klassen und Manager erstellt um den Lauf vom Programm zu steuern (siehe dazu die Doxygen Doku am Ende dieser Seite).
Ein File wird beim Programmstart bereits automatisch geladen, welches in den mitgelieferten Files enthalten ist (Default: "King James Bible.txt").
Mittels der Menüleiste am oberen Teil des Programms können neue Files geöffnet werden ( File--> Open) die dann sofort geladen und verarbeitet werden. Mittel File->Quit oder dem X rechts oben am Fenster kann das Programm geschlossen werden.
Links befindet sich ein Editor mit einer Listbox mit einer Auswahl an Textmustern für die Bildung von Phrasen als Netzwerke.
Es können auch mehrere Muster ausgewähltwerden indem man während der Auswahl mit der Maus die Ctrl Taste gedrückt hält. Diese werden dann mittels "Oder" verknüpft und im Regex-Vergleich verwendet.
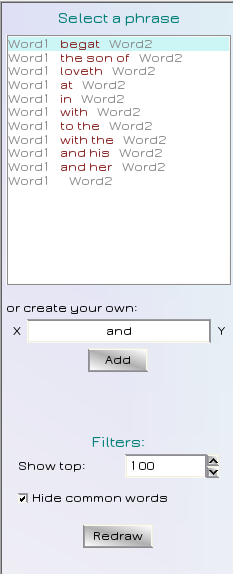
Mittels einer Eingabe in der Editbox darunter, können eigene Muster eingegeben werden. Nach der Eingabe muss "Add" gedrückt werden um sie hinzuzufügen. Daraufhin wird sie automatisch ausgewählt und alles andere abgewählt und ein neues Nodenetzwerk generiert.
Es gibt 2 Filter. Der eine limitiert die maximal angezeigten Resultate (Show top) als integer zahl, der zweite blendet möglicherweise ungewollte Wörter aus, die vorher einer internen fixen StopWord list hinzugefügt wurden.
Nach Änderung an den FIltern muss "Redraw" gedrückt werden um die Anzeige zu erneuern.
Bei der Anzeige wurden 2 Farben für die Font verwendet. Das hellere grünliche Blau bedeutet, dass der Node mehr eingehende Verbindungen besitzt. Dunkelblau bedeutet mehr ausgehende Verbindungen. Die größe der Nodes ist abhängig von der allgemeinen Häufigkeit des Wortes im Texts. Die Pfeildicke hängt von der Anzahl der ein- und ausgehenden Verbindungen ab, durch die auch eine die Transparenz des Pfeils bestimmt wird. Der Pfeilkopf ist skaliert in Abhängigkeit der Anzahl der Verbindungen von einem Node zu einem bestimmten anderen Node.


