Hallo liebe Hall Of Fame Besucher,
Im Sommersemester 2005 haben Jonathan Thaler und Michael Ionita sich am Beamtree Algorithmus versucht.
Es war nicht immer einfach das Paper zu verstehen denn es fehlte die grundlegende Information. Doch mit Hilfe anderer Informationsquellen ist es uns dann schlussendlich gelungen das Programm fertig zu stellen.
Es war leider zu wenig Zeit, und es gab zu viele andere Prüfungen, um die Ansicht auf den Beamtree in 3D zu implementieren, doch im Grunde nützt der Beamtree auch die 3te Dimension um mehr Hirarchische Information darstellen zu können.
Das Ganz haben wir in JAVA 2D realisiert. Für mich persönlich war es die erste Erfahrung mit Fensterdarstellungen und Knöpfen usw.
Mein Kollege (Thaler) dagegen war schon sehr versiert und enthusiastisch.
Im Großen und ganzen hat es uns Spaß gemacht das Paper zu präsentieren und den Algorithmus zu schreiben. Ich hoffe dass andere Gruppen in Zukunft auch Spaß daran finden InfoVis auszuprobieren denn es ist ein sehr interessantes Gebiet das sich gerade im Wachstum befindet.
Das Paper
Es wurde von Frank van Ham, Jarke J. van Wijk geschrieben und erklärt wir man von einem normales Treemap auf einen Beamtree kommt. Dabei verweisen sie auch auf Constrains (Einschränkungen) beim Skalieren des Treemap auf den Beamtree.
Der Beamtree ist nichts weiter als ein Baum der aus Beams (Röhren) besteht. Die Blätter sind auf ihre Parents drauf skaliert damit sie nicht mehr so viel Platz einnehmen (bei einem Gewöhnlichen Treemap nehmen die Blätter den gesamten Bildschirmplatz ein). Diesen Platz will man nützen um Hirarchie Informationen darzustellen. ALso werden die Kinder skaliert. Dabei muß man darauf achten dass das Konstrukt nicht ausseinanerfällt. Es könnte z.B sein dass Blätter plötzlich irgendwo im Raum auftauchen und, anscheinend, niergendwo dazu gehören. Deshalb muß man diese besagten Constrains einhalten:
1. N has only leaf nodes as children: In this case we don’t need to compute constraints, since leaf nodes get scaled with their parent by definition.
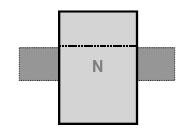
2. N has only non-leaf nodes as children: To avoid the structure from breaking up into separate pieces we use the front edge of the rectangle representing the first child of N as a lower bound and the back edge of the rectangle representing the last child of N as an upper bound.
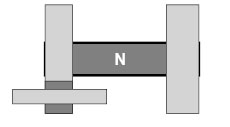
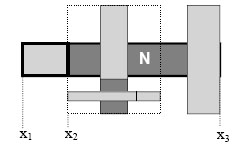
3. N has both leaf and non-leaf nodes as children: We can use the back edge of the last child node of N (i.e. x3) in the same manner as we did in the previous case. Since N also has leaf nodes as children we have to take space for them into account to avoid overlapping structures. Bound x2 is equal to the front edge of the bounding box encasing the first non-leaf child of N. Since we also know the total size of all leafnodes S(L) and the total size of all child nodes S(N), we can derive x1 by solving:
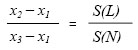
S(L) = total size of all the leaf nodes.
S(N) Total Size of all the Child nodes.
Implemented Methods
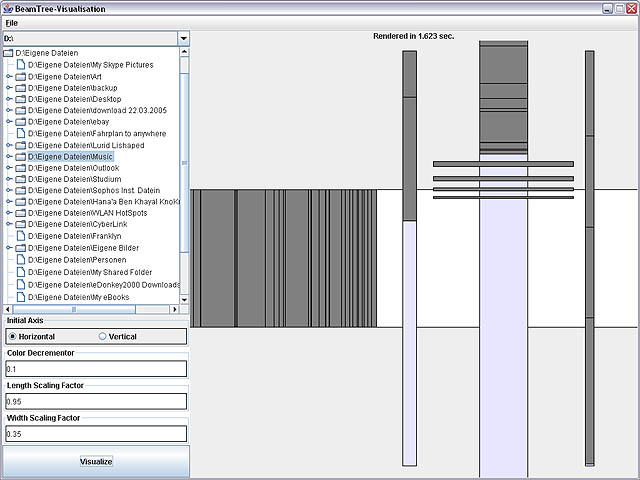
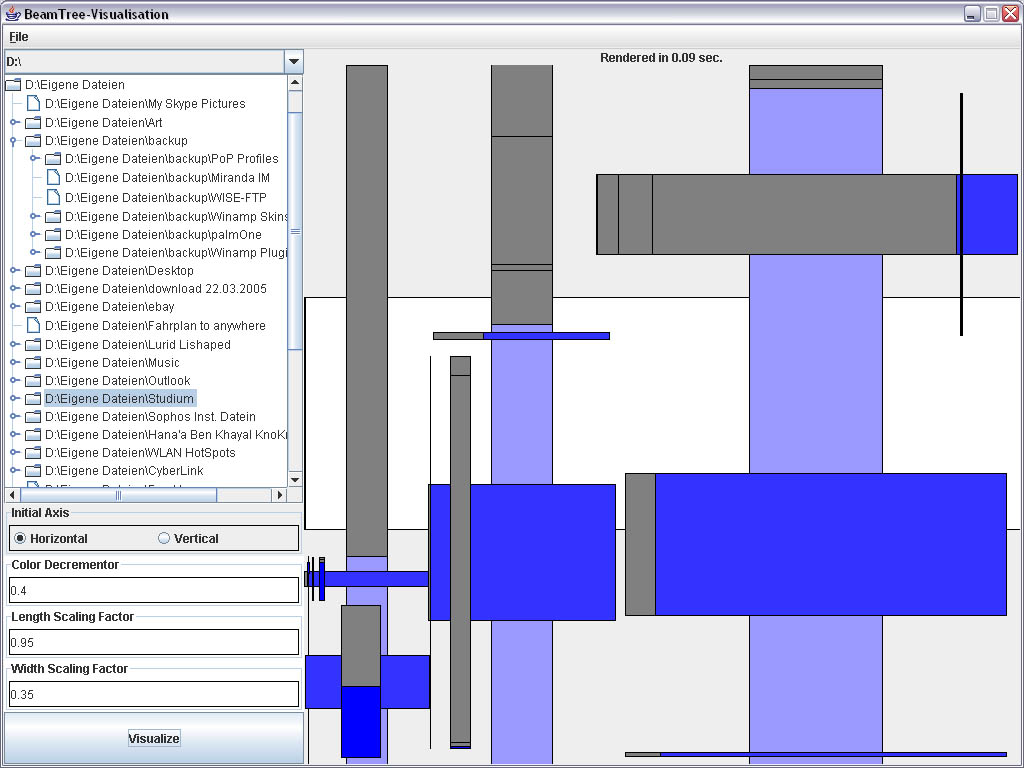
Wir haben die Möglichkeit eingebaut den Baum Horizontal und Vertical zu rendern.
Außerdem haben wir einen Color Decrementor. Dieser ist per Default aus 0.1 gesetzt und bedeutet dass die Farbe um in 0.1 Schritten decrementiert wird.
Die Root ist immer weiß,
Die Parents nähern sich immer mehr dunkelblau an und
die Children sind stets grau.
Es gibt auch einen Scaling Factor für Length und für Width. Im Paper wird 0.95 für Length und 0.35 für Width vorgeschlagen.
Natürlich kann man sich ein beliebiges Verzeichnis aussuchen das man darstellen möchte und deshalb gibt es eine Baum-Verzeichnis-struktur duch die man sich durchclicken kann.
Have Fun, und alles Gute für euer Studium,
Yours Michael Ionita && Jonathan Thaler.
Hier noch ein paar Screenshots: