| Autoren | | | Überblick | | | Algorithmus | | | Daten | | | Implementierung&Installation | | | Bedienung des Programmes | | | Erweiterungen | | | API-Doku | | | Referenzen |
Pixel Bar Charts sind eine von Daniel Keim et al. [1] entwickelte
pixelbasierte Visualisierungsmethode, die darauf abzielt, den am Bildschirm zur Verfügung stehenden Platz bestmöglichst auszunützen, indem jeweils ein Datenwert auf ein Pixel abgebildet wird.
Da eine optimale zweidimensionale Sortierung von Punkten aufgrund der Vielzahl an zu beachtenden Constraints vermutlich ein np-hartes Problem darstellt, schlagen die Autoren in [1] eine heuristische Methode vor, die darauf basiert, die Quantile in zwei Dimension zu schätzen und anschließend die Daten in das von den Quantilen erzeugte "Gitter" einzusortieren. Mit Hilfe geschickter Vorsortierung und effizienter Datenstrukturen ist es möglich, den Aufwand für die Sortierung auf O(n log n) zu senken. Für Details zum Algorithmus siehe [1].
Das Problem des Algorithmus besteht darin, dass es einerseits so gut wie nie möglich ist, alle Datenwerte zu platzieren. Daraus resultiert jedoch auch, dass viele Pixel mehrfach mit den gleichen Datenpunkten belegt werden müssen, was bei ungünstig verteilten Daten dazu führen kann, dass große Teile des Bildes ein und denselben Wert darstellen (optimal funktioniert der Algorithmus bei IID verteilten Zufallszahlen; hier können fast 100% der Daten platziert werden; mit steigender Korrelation der Dimensionen können immer weniger Punkte platziert werden).
Obwohl Pixel Bar Charts ursprünglich für die Visualisierung von Geschäftsdaten angewandt wurden, entschlossen wir uns, diese Technik für etwas gänzlich anderes einzusetzen.
CFD-Simulationen für die Simulation von Strömungsvorgängen produzieren hochdimensionale (15-25 Dimensionen) und große (mehrere zigtausend bis Millionen Punkte) zeitabhängige Datenmengen, welche mit herkömmlichen Visualisierungsmethoden aus der Scientific Visualization (Volume Rendering, Isosurface Rendering, Streamlines,...) nur sehr schwer in einer für den Betrachter verständlichen Form dargestellt werden können. Daher wird in letzter Zeit verstärkt im Bereich der Feature based visualization geforscht, welche versucht, interessante Untermengen aus den Daten zu extrahieren, indem dem/der UserIn die Möglichkeit zur interaktiven Fokussierung von Daten und ein visuelles Feedback in anderen Darstellungen der gleichen Daten gegeben wird (siehe auch [2], [3]).
Wir haben die Idee der Pixel Bar Charts an Daten aus Strömungssimulationen angepasst, indem wir als Aufteilungsattribut in x-Richtung die Zeit herangezogen haben und in jedem Balken drei weitere Dimensionen für die x-/y-Ordnung und die Farbe auswählbar gemacht haben. Sichtbar sind also t Zeitschritte von n-dimensionalen Datenpunkten, wobei maximal 3 Dimensionen gleichzeitig visualisiert werden können. Zusätzlich gibt es die Möglichkeit, Daten in einem Zeischritt interaktiv zu markieren (zu brushen) und so die Verteilung von Punkten in anderen Zeitschritten sichtbar zu machen.
Als Programmiersprache wurde aufgrund der zu erwartenden Performanceengpässe und der Speicherplatzanforderungen C++ gewählt.
Bei der Implementierung wurde besonderen Wert auf Plattformunabhängigkeit gelegt. Daher kam das
QT-Framework zum Einsatz, welches eine einfache Möglichkeit
für GUI-Entwicklung unter Linux, MacOS X und Windows bietet, und außerdem einen Plattformübergreifenden Build-Mechanismus besitzt.
Das Programm kann mit
qmake pbc.pro
make
unter Linux bzw.
qmake pbc.pro
nmake
unter Windows erzeugt werden. Alternativ dazu kann mit
qmake -t vcapp -o pbc.vcproj pbc.pro
ein Projektfile für Benutzer der Visual Studio-Entwicklungsumgebung erzeugt werden. Wird die Version 7.1 (VS .NET 2003) verwendent, muss
pbc.vcproj durch pbc.dsp ersetzt werden, weil es der Hersteller dieses Produktes offenbar für ein Software-Feature hält, die Semantik von
Dateiendungen von Version zu Version zu ändern und Fileformate nicht abwärtskompatibel zu halten.
Nach dem Start des Programmes kann mit "File->Open" ein Datensatz geladen werden. Nach dem Laden können im Bereich "Data Controls" die darzustellenden Dimensionen ausgewählt werden.
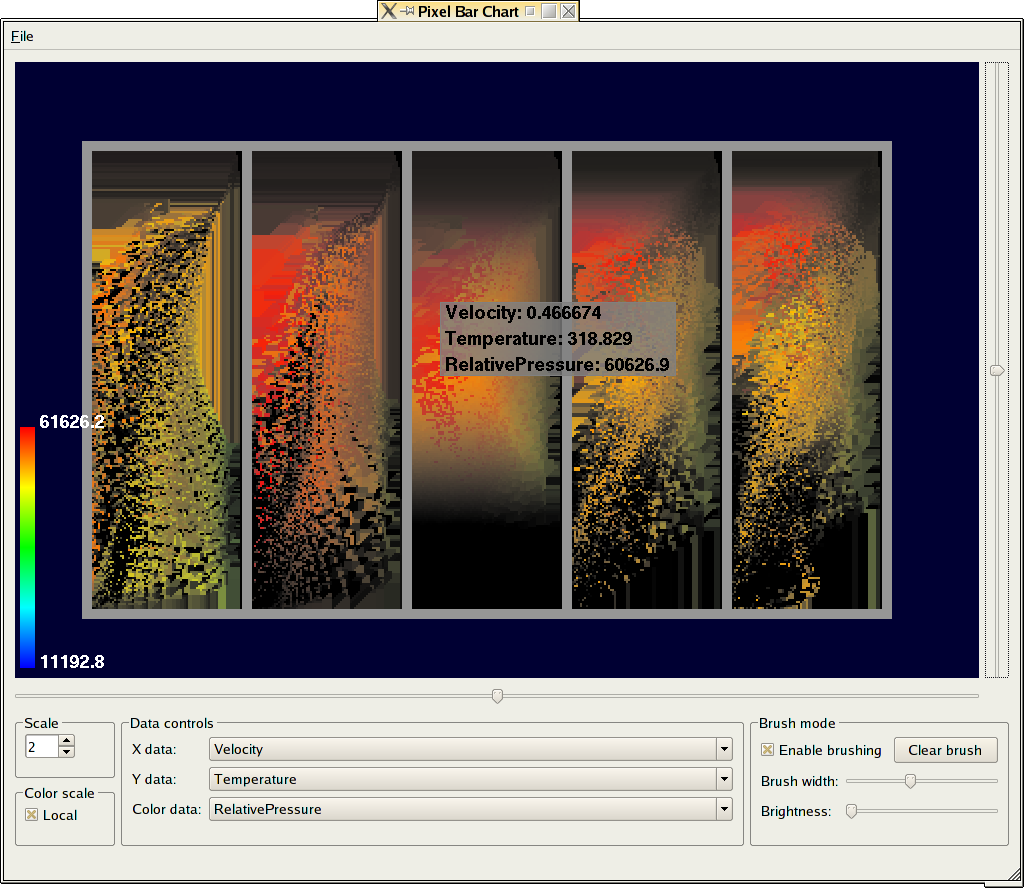
Danach werden im Render-Window immer die ausgewählten Daten angezeigt. Jeder Balken repräsentiert dabei einen Zeitschritt aus den Daten.
In der linken unteren Ecke befindet sich eine Farblegende, die dem/der UserIn anzeigt, welche Farben auf welche Datenwerte abgebildet werden. Dabei ist darauf zu achten, welcher Color scaling mode ausgewählt ist. Zu Beginn ist dies der Global scaling mode, was bedeutet, dass das globale Minimum (über alle Zeitschritte) auf gesättigtes Blau (HSV(240,255,255)) und das globale Maximum auf gesättigtes Rot (HSV(0,255,255)) abgebildet wird. Zwischen diesen Farben wird dann entsprechend den Datenwerten linear interpoliert.
Klickt man im Bereich "Color scale" den Button "Local" an,
werden die Farben hingegen für jeden Zeitschritt (Balken) auf die lokalen Minima/Maxima skaliert. Die aktuell gültigen Minima/Maxima werden neben der Farblegende angezeigt (bei lokaler Skalierung sind dies immer die Werte, die für den Balken, über dem sich die Maus im Moment befindet, gelten):

Um die interaktive Exploration der Daten zu unterstützen, können die zu jedem Bildpunkt gehörenden Daten mit einem Klick auf die rechte Maustaste angezeigt werden. Weiters kann im Bereich "Scale" ein Zoomfaktor eingestellt werden, um feinere Details sichtbar zu machen. Der Zoomfaktor ist im Hinblick auf die pixelbasierte Idee nur ganzzahlig einstellbar. Nichtganzzahlige Skalierungsfaktoren würden zu Aliasing bzw. Blurring führen.
Mit den Slidern neben dem Render-Window kann der dargestellte Bereich verschoben werden (siehe Screenshot unten).
Ein weiteres Feature ist der Brush-Mode, welcher mit einem Klick auf "Enable Brushing" aktiviert werden kann:
Im Brush-Mode können Datenbereiche in einem Zeitschritt interaktiv selektiert werden (in den Focus gerückt werden), gleichzeitig werden in den anderen Zeitschritten die entsprechenden Daten gekennzeichnet (die nicht gebrushten Daten - die Context-Werte werden dabei mit geringerer Helligkeit und Sättigung dargestellt; der Grad der Helligkeit/Sättigung kann dabei ebenfalls mit dem Slider "Brightness" eingestellt werden).
Mit dem Slider "Brush width" kann die Breite des Brushes verstellt werden (dabei kommt "Smooth Brushing" zum Einsatz, was bedeutet, dass der Punkt, auf den geklickt wurde, mit maximalem Focus-Wert dargestellt wird, die umliegenden Werte jedoch entsprechend ihrer Entfernung zum gewählten Datenwert an Wichtigkeit verlieren). Für Details zur Implementierung von Smooth Brushing und für weitere Anwendungen siehe auch [2], [3].
Denkbar wäre eine Einbindung in bestehende Frameworks für Feature Based Flow Visualization, etwa das SimVis-System. In Kombination mit anderen Views (Scatterplots, Histogrammen, 3D Views für die Darstellung der räumlichen Dimensionen) könnten Pixel Bar Charts sicherlich einiges dazu beitragen, Einsicht in die Daten zu bekommen.
Allerdings wäre es vorher notwendig, den Sorting-Algorithmus gründlich zu überdenken und gegebenenfalls zu modifizieren, damit die Ergebnisse hier auch bei ungünstig verteilten bzw. stark korrelierten Daten befriedigender ausfallen, als es derzeit der Fall ist.