Despite its lacking physical validity, the Phong illumination model [42] is still widely used in computer graphics. Its popularity is most probably based on its simplicity. Phong's model is a local illumination model, which means only direct reflections are taken into account. While this may not be very realistic, it allows illumination to be computed efficiently. The model consists of an independent ambient, diffuse and specular term. It has the following parameters:
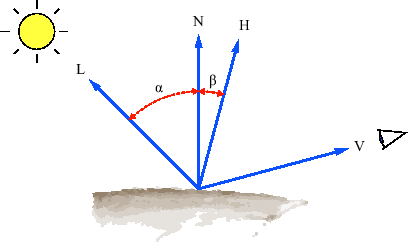
These parameters are illustrated in Figure 3.5. Additionally, the half-way vector
![]() is displayed.
is displayed.
 |
Three constants, ![]() ,
, ![]() , and
, and ![]() , control the contribution of each term to the final light intensity. The shaded color is computed by multiplying the input color (e.g. the color of a sample as obtained through the transfer function) by the sum of the three terms (see Equation 3.7). We assume here that the color of the light source is always white and can therefore disregard its color contribution.
, control the contribution of each term to the final light intensity. The shaded color is computed by multiplying the input color (e.g. the color of a sample as obtained through the transfer function) by the sum of the three terms (see Equation 3.7). We assume here that the color of the light source is always white and can therefore disregard its color contribution.
The ambient term (Equation 3.8) is constant. Its purpose it to simulate the contribution of indirect reflections, which are otherwise not accounted for by the model.
The diffuse term (Equation 3.9) is based on Lambert's cosine law which states that the reflection of a perfect rough surface is proportional to the cosine of the angle ![]() between the light vector
between the light vector ![]() and the surface normal
and the surface normal ![]() .
.
The specular term (Equation 3.10)adds an artificial highlight to simulate specular reflections. For computing the specular term, Blinn proposed to use the half-way vector ![]() [1], which is a vector halfway between the light vector and the view vector. The specular lighting intensity is then proportional to the cosine of the angle
[1], which is a vector halfway between the light vector and the view vector. The specular lighting intensity is then proportional to the cosine of the angle ![]() between the half-way vector
between the half-way vector ![]() and the surface normal
and the surface normal ![]() raised to the power of
raised to the power of ![]() , where
, where ![]() is called the specular exponent of the surface and represents its shininess. Higher values of
is called the specular exponent of the surface and represents its shininess. Higher values of ![]() lead to smaller, sharper highlights, whereas lower values result in large and soft highlights.
lead to smaller, sharper highlights, whereas lower values result in large and soft highlights.
Despite the low complexity of this illumination model, shading still has considerable impact on performance. One way to speed up the evaluation is the use of reflectance maps [52], which contain pre-computed illumination information. However, the use of such data structures requires a considerable amount of additional memory and can lead to cache thrashing. Furthermore, they have to be re-computed every time the illumination properties change. Thus, we choose to evaluate the illumination model on-the-fly. The most time consuming part of the model is the exponentiation used in the specular term. However, since this is a purely empirical model, every function that evokes a similar visual impression can be used instead of the exponentiation. Schlick therefore proposed to use the following approximation [47]:
| (3.11) |
|
|
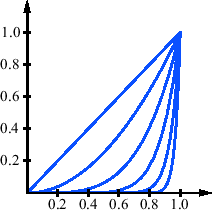
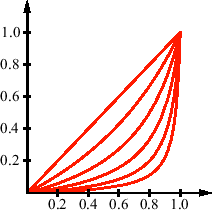
Schlick's approximation is generally much faster to compute and yields to very similar results (see Figure 3.6). Figure 3.7 shows a comparison of the original function and the approximation for different values of ![]() .
.
Our system uses the Phong illumination model with Schlick's approximation for the specular term. One directional light source is supported. This allows us to compute shading at little cost. This setup is well suited for medical applications, where the user generally does not benefit from (and might even be disturbed by) increased photorealism.
![\includegraphics[width=6.5cm]{algorithm/images/head_phong.eps}](img106.png)
![\includegraphics[width=6.5cm]{algorithm/images/head_schlick.eps}](img107.png)